|
I am a Second year PhD student at the University of Illinois, Urbana Champaign, advised by Prof. Dilek Hakkani-Tur and Prof. Hao Peng. Previously I worked at the Bing Ads Team at Microsoft, where I worked on Dense and Generative retrieval for Ads Snippets. I also spent 3 months as a Research Assistant at MBZUAI working with Prof. Monojit Choudhury. I graduated from Indian Institute of Technology Kanpur in 2021 with a bachelors degree in Electrical Engineering. While at IIT Kanpur, I worked with Prof. Ashutosh Modi and Prof. Arnab Bhattacharya Email / CV / LinkedIn / Google Scholar / Twitter |

|
|
My research is centred around Large Language Models. More specifically, I am interested in building next generation LLMs that can continually and scalably learn from interactions. To this end, my work includes
|
|
|
|
|
|
|
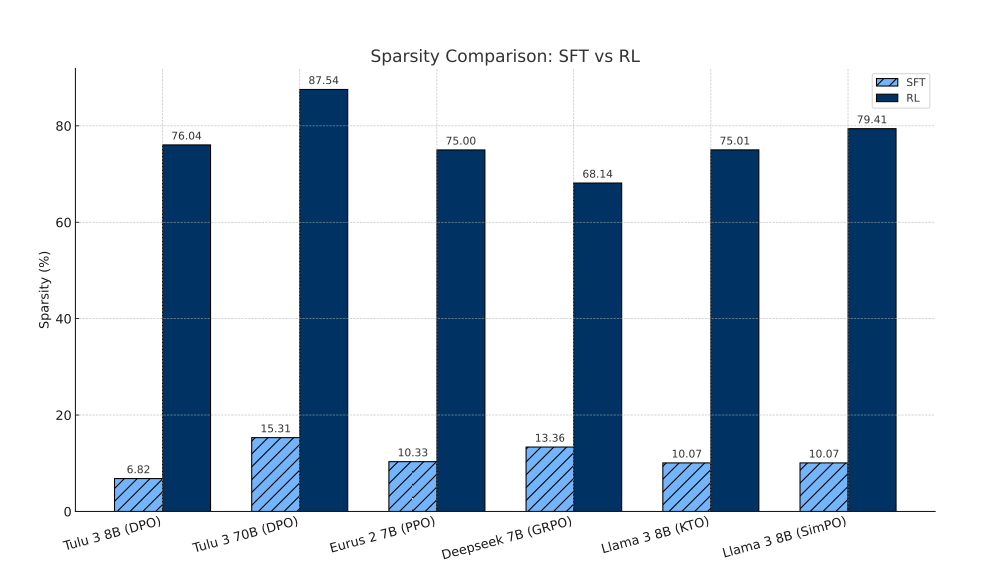
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, Hao Peng NeurIPS 2025 RL causes sparse updates to a base model. |

|
Sagnik Mukherjee*, Abhinav Chinta*, Takyoung Kim, Tarun Anoop Sharma, Dilek Hakkani-Tür ICML 2025 Structure induction improves error identification. |
|
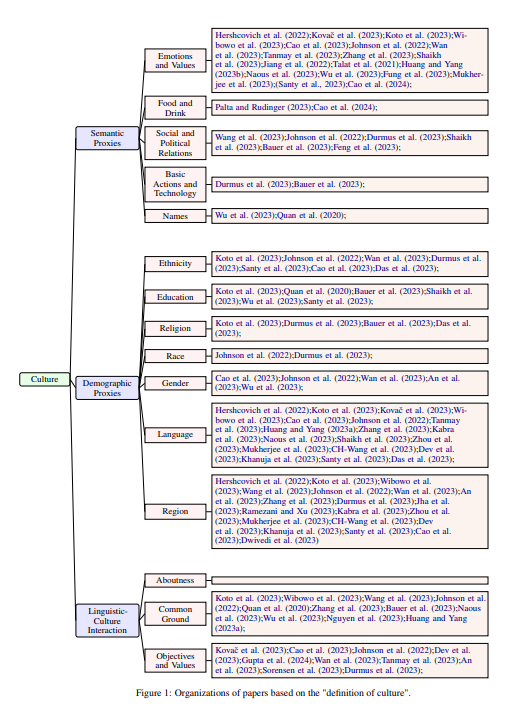
Muhammad Farid Adilazuarda*, Sagnik Mukherjee*,Pradhyumna Lavania, Siddhant Singh, Ashutosh Dwivedi, Alham Fikri Aji, Jacki O'Neill, Ashutosh Modi, Monojit Choudhury EMNLP 2024 (main) We propose a taxonomy of how the community has been studying culture so far. |
|
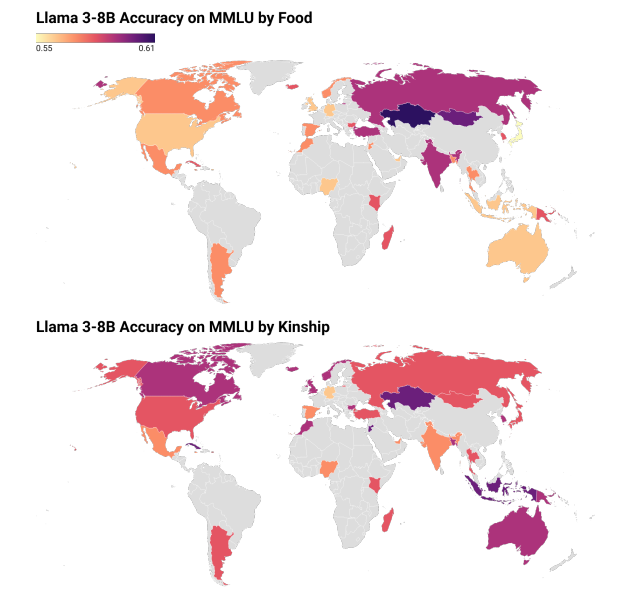
Sagnik Mukherjee∗, Muhammad Farid Adilazuarda∗, Sunayana Sitaram, Kalika Bali, Alham Fikri Aji, Monojit Choudhury EMNLP 2024 (main) Studies the (in)-efficacy of sociodemographic prompting. |
|
|